April 20th, 2024

{ Engineering }
Manoeuvring challenges posed by out-of-the-box configurations.

Obi Uchenna David
We are attracted to the convenience of out-of-the-box setups. They offer some level of efficiency but come with their fair share of challenges. In this article, we’ll examine these challenges and learn how to handle them like experts.
The Psychology Behind Defaults.
Our Biases.
When it comes to default configurations, cognitive biases can significantly impact decision-making. For example, anchoring bias makes people overly dependent on information received early in the decision-making process, which makes them accept default settings without question. Status quo bias makes people stick with what is currently available even when it may not be the best option. People with choice-supportive bias will defend past choices, even if they were based on defaults.
How this shapes engineer behaviour during software setup.
Regarding software installation and setup, default configurations have a big say in what the engineer can choose. Think about the typical situation where an engineer installs new software. During installation, they’ll see several options, prompts, and default settings for certain parameters.
These default configurations simplify the installation process for a hassle-free experience. However, they also significantly impact the engineer’s decisions. Engineers often overlook default settings for various reasons.
One, the software provider presents default settings as the best or safest choice. The engineers, in turn, believe these are the best options for their system and are more likely to accept them without question.
Secondly, default settings are usually created with the average customer or the most frequent use cases in mind and might not accurately represent some engineers’ needs. Some engineers, especially at the early stages, still need to gain the skills or knowledge necessary to understand when default settings are inappropriate for their use case. As a result, they automatically accept the software’s default values.
Case in Point: Mikrotik.
The default configurations of MikroTik routers, especially the default passwords, significantly impact security. In the past, MikroTik routers came with default login information, like the username “admin” and either an empty or well-known default password. Although this method was helpful for early setup, it seriously endangered security.
Some engineers, especially those with limited technological knowledge, had yet to realise how important it was to change default passwords or may have believed the default credentials were sufficient. As a result, many MikroTik routers were open to cyber attacks.
Due to the widespread use of default passwords for these routers, many security problems and breaches happened. These incidents involved attackers gaining unauthorised access and potentially compromising important network configurations and data. Occurrences like these highlight the importance of updating default passwords and applying robust security procedures when managing networks.
In the end, the outcome with the MikroTik router default passwords is a dramatic illustration of how default settings—in particular, default passwords—can have far-reaching effects on security. It emphasises how important it is for engineers to be concious of safety by changing default passwords and putting security measures in place, and how important it is for manufacturers to prioritise security in default configurations.
Case Studies.
Nginx.
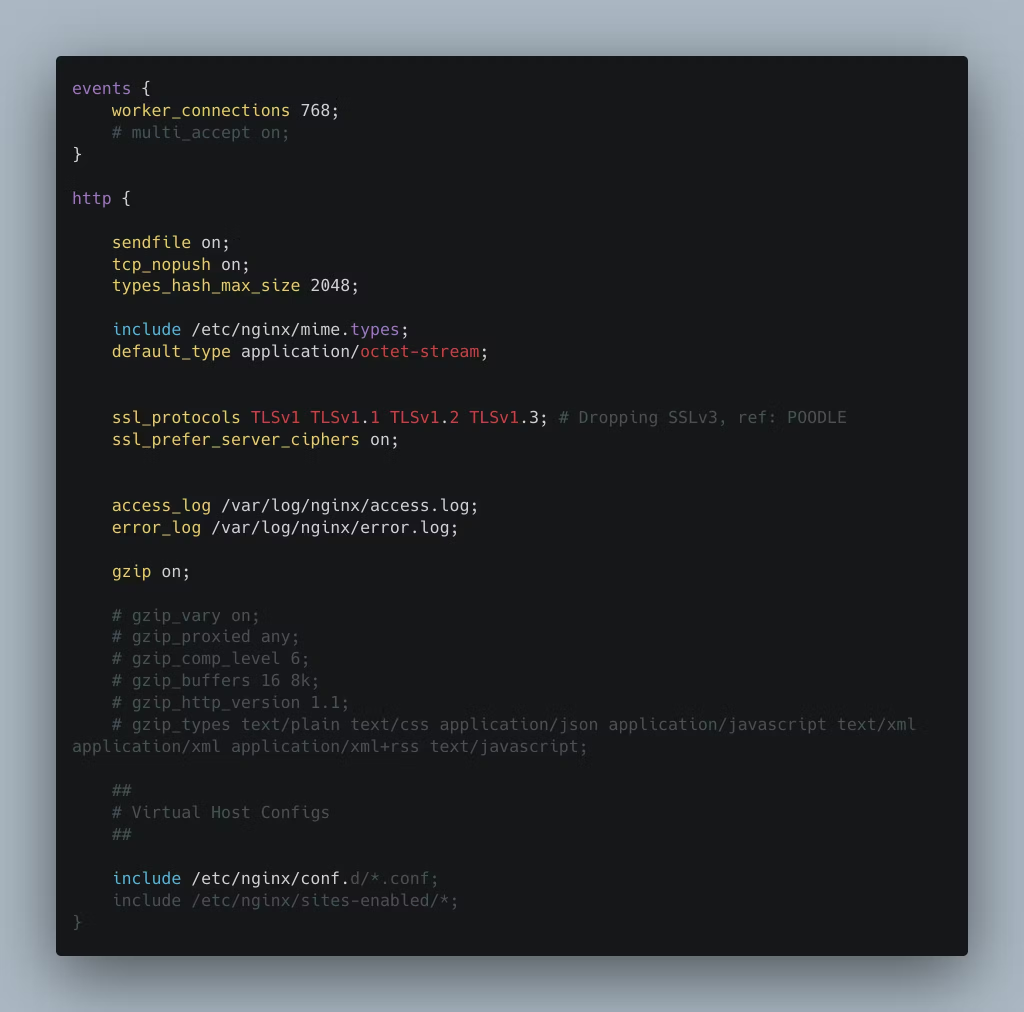
Nginx, a key component of web infrastructure, is well-known for its outstanding performance and versatility. Like any software, though, it has default settings that may affect performance and security. Let’s examine some Nginx default settings. We’ll explore their implications and offer suggestions to optimise them for better protection and efficiency.
The components under review are:
- worker_processes:
- Default set to auto, automatically determines CPU cores.
- Spawns one worker process per core.
- Efficiently utilises CPU resources.
- worker_connections:
- Default value is 768.
- Balances resource efficiency and handling incoming connections.
- Can be adjusted based on server resources and traffic volume.
- access_log:
- Logs details of client requests and server responses.
- Provides valuable insights into server usage and traffic patterns.
- Helps in troubleshooting, performance analysis, and security auditing.
Within our team, we recently faced an urgent problem: increased heavy traffic caused one of our server’s worker connections to fill to its maximum capacity. This problem resulted from the fact that we never updated the configuration since we first created the server, which left it unable to handle the spike in requests even though the server could.
When one of our downstream services started showing extended response times, we realised how serious the problem was and started looking into the source. This research led directly to an overlooked discrepancy in our server setup, which we missed due to a failure to change worker connections.
Another crucial part to pay attention to is the access log settings. Despite their apparent simplicity, these settings contain nuanced details that should be considered carefully.
While invaluable for monitoring and analysing server activity, access logs can become a space-consuming burden if not set to auto-rotate. Without this critical functionality enabled, access logs gather over time, eating disc space and potentially causing server performance concerns. Auto-rotation ensures that access logs are periodically archived or shortened, keeping them from bloating and freeing up disc space for other critical purposes. Failure to configure access logs with auto-rotation exposes server administrators to storage restrictions and operational inefficiencies, emphasising the significance of proactive log management techniques.
MongoDB Cloud.
Beginning our examination of MongoDB Cloud, we’ll examine its default settings, emphasising backup and autoscaling functionality. These default parameters influence how MongoDB Cloud works, particularly regarding data protection and automatically modifying resources based on workload changes.
Our workload varies and is less intense throughout the day, peaking at night. Similarly, MongoDB cluster utilisation fluctuates during the month, peaking at the start and finish and declining in the middle. Rather than sticking to a set MongoDB cluster size, we used autoscaling to adjust to these dynamic patterns. As a result, our cluster can quickly scale up or down in response to demand, guaranteeing constant peak performance and efficient use of available resources.
The autoscaling method of MongoDB Cloud has its drawbacks. When the average CPU and memory usage in the last hour surpasses 75% of available resources, scaling up takes place. On the other hand, scaling down occurs when the 24-hour average of CPU and memory usage falls below 50% (We couldn’t edit this functionality). However, MongoDB forced us into a larger, more expensive cluster size than needed because of our daily usage pattern.
After thoroughly examining our data and implementing optimisations like index addition and query optimisation, we successfully reduced the size of our MongoDB Cloud deployment to a single tier. This tactical change increased the effectiveness of data access and saved us substantial money.
In addition to optimising our MongoDB Cloud deployment, we also revamped our backup strategy.
MongoDB Cloud has a very verbose backup strategy –
- Hourly – every 6 hours kept for 2 days.
- Daily – every day kept for 1 week.
- Weekly – every week kept for 1 month.
- Monthly – every month kept for 1 year.
- Yearly – every year kept for 1 year.
Given the nature of the data stored in MongoDB, such as application event and notification data, we found the default backup configuration overly extensive. Retaining backups of application event data for months proved unnecessary for our requirements. Therefore, we took proactive steps to tailor the backup settings to better align with our needs, ensuring that we optimise our backup strategy for efficiency and relevance to our data retention policies.
Mitigating Risks and Best Practices.
Navigating the domain of defaults demands a strategic mindset and a dedication to best practices since default configurations can expose systems to security vulnerabilities or impede scalability and performance. In our analysis of navigating out-of-the-box setups, here are key tactics to recognise, manage, and reduce the risks associated with default settings.
In our analysis of navigating out-of-the-box setups, here are key tactics to recognise, manage, and reduce the risks associated with default settings.
Observability.
In general, observability is the extent to which you can understand a complex system’s internal state or condition based only on knowledge of its external outputs.
Observability relies on logs, metrics, and traces to achieve complete visibility into a system, as each pillar provides unique insights necessary to identify the cause and timing of incidents.
Observability is a vital concept in system monitoring and troubleshooting that provides a thorough understanding of a system’s internal condition through its exterior outputs alone. Fundamentally, observability depends on the capacity to use logs, metrics, and traces in concert to extract information about system performance, behaviour, and possible problems.
- Logs provide a chronological account of activities over time and function as a detailed record of events and actions within a system. Engineers can examine logs to identify specific events, faults, or anomalies that may affect system functionality, making root cause analysis and debugging more efficient.
- Metrics offer numerical assessments of many aspects of the system, including memory usage, CPU usage, and request latency, among other performance indicators. Engineers can get critical insights into system health and performance trends by tracking real-time metrics. It allows for proactive capacity planning, resource allocation, and performance optimisation.
- Traces record details about every stage and element involved in the process, providing a detailed picture of the requests and transactions that flow from start to finish across distributed systems. Engineers can compare traces with logs and metrics to discover bottlenecks, latency problems, and errors to comprehensively understand the system’s behaviour and performance.
Logs, metrics, and traces collectively form the pillars of observability, providing complementary insights into different aspects of system operation.
Load Testing.
Load testing becomes a crucial procedure for reducing the difficulties caused by default settings and guaranteeing the resilience and dependability of software systems under different loads and stresses. By putting applications through simulated loads and stress situations, load testing gives significant insights into system performance, scalability, and resilience. This enables engineers to find and fix bottlenecks, vulnerabilities, and performance issues before they affect end users. One popular load-testing tool we use is k6.
You can define a simple test script as follows
and run it using
k6 run -u 5000 -i 100 k6test.js
These commands execute a load test using the k6 tool with specific parameters:
- k6 run: This command runs a k6 test script.
- -u 5000: This flag specifies the number of virtual users (VUs) to simulate during the test. In this case, it’s set to 5000, meaning that the load test will simulate 5000 concurrent users.
- -i 100: This flag specifies the number of iterations each virtual user will execute. In this case, it’s set to 100, meaning that each of the 5000 virtual users will execute 100 iterations of the test script.
- k6test.js: This is the filename of the k6 test script to be executed.
You can update configurations to suit your needs depending on how your server holds up.
Regular updates and Patch management.
Patch management and routine updates are crucial cybersecurity and system administration procedures designed to lessen the risks associated with default configurations. Companies enhance their systems’ security, stability, and functionality by applying patches and routinely upgrading software. It substantially lowers the danger of bad actors exploiting their systems and fixes vulnerabilities present in default settings. We explore the core ideas, best practices, and tactics that enable enterprises to strengthen their defences, improve system resilience, and protect against changing threats in today’s dynamic digital environment. We examine regular updates and patch management as proactive measures to mitigate challenges posed by default settings.
Consult the documentation.
Whether diagnosing a technical issue, setting up a system, or learning how to use a new product, documentation is an invaluable resource that enables us to handle difficulties with confidence and knowledge. So, if all else fails, consulting the documentation assures that you have the knowledge and advice you need.
Next article


Chima Ataman;
{ Team Lead Infrastructure } Cowrywise